AlphaCode2
20240422wwz投稿
一款AI编程工具
2022年初,曾经发布过Alpha Go 的 deepmind公司发表了AlphaCode,它是一个人工智能系统,可以自动生成竞赛级代码。这项研究登上了《Science》封面。AlphaCode 在 Codeforces 网站上 5000 名用户解决的 10 次比赛进行了测试,总体排名位于前 54.3%,也就是说它击败了 46% 的参赛者 。DeepMind 估计,AlphaCode 系统的 Codeforces rating 为 1238,使其过去六个月内在该网站上参与比赛的用户中排名前 28%。
Codeforces 创始人 Mike Mirzayanov 表示:“我可以肯定地说 AlphaCode 的结果超出了我的预期。对此,有人怀疑我这么乐观,因为他们认为即使在简单的竞赛问题中,参赛选手不仅需要编写常规算法,还需要创新新算法,而这一部分是最困难的。但目前看来,AlphaCode 的表现与一个前途无限的人类参赛者相当,我迫不及待地想看看未来会发生什么!”
来自谷歌的世界级竞赛程序员 Petr Mitrichev 表示:“解决竞争性编程问题是一件非常困难的事情,需要良好的编码技能和人类解决问题的创造力。AlphaCode 在这一领域取得的进展给我留下了深刻的印象,很高兴看到 AlphaCode 使用语言理解能力来生成代码并进行随机探索以创建新的解决方案。”
可以在alphacode.deepmind.com查看alphacode的代码。
在2023年末,deepmind推出了前代AlphaCode的改进版本AlphaCode 2。它的表现更加出色,击败了85%的参赛者,具体的细节请见下文。(注:下文转载自来源1和来源2)
【中文翻译】 AlphaCode 2 技术报告
AlphaCode 团队,谷歌 DeepMind
AlphaCode (Li et al., 2022) 是首个在竞赛编程中达到中等参赛者水平的人工智能系统,这是一个涉及高级数学、逻辑和计算机科学的复杂推理任务。本文介绍了 AlphaCode 2,这是一个全新的、性能大幅提升的增强系统,由 Gemini (Gemini Team, Google, 2023) 提供技术支持。AlphaCode 2 结合了强大的语言模型和专门定制的搜索及重新排名机制。在与原始 AlphaCode 相同的平台上进行评估时,我们发现 AlphaCode 2 解决了比原版多出 1.7 倍的问题,并且其表现超越了 85% 的竞赛参与者。
引言
竞赛编程是评估编写代码技能的重要标准之一。参与者需要在限定时间内解决涉及关键思维、逻辑及对算法、编程和自然语言理解的复杂问题。因此,它是衡量高级推理和解决问题能力的重要基准。
AlphaCode (Li et al., 2022) 是首个在此任务上达到竞争水平的人工智能系统。它的升级版,AlphaCode 2,集成了多个基于 Gemini (Gemini Team, Google, 2023) 的模型,成为一个大幅提升性能的系统。在 Codeforces平台上的评估显示,AlphaCode 2 解决了43%的问题,几乎是原始 AlphaCode(25%)的两倍。尽管其前身的表现与中等水平的参赛者相当,我们估计 AlphaCode 2 平均达到了前 15% 的水平。
采用 Gemini 作为 AlphaCode 2 的核心模型是实现这一突破性能的关键。AlphaCode 2 的成功凸显了 Gemini 在灵活性和适应性方面的优势,我们能够对其进行针对性的微调,优化其在包括代码生成和代码重排序等多个不同任务上的性能。
总体系统
AlphaCode 2 依托于强大的大型语言模型,并结合了专为竞赛编程定制的高级搜索和重新排名机制。如图 1 所展示,它的主要组成部分包括:
- 一系列策略模型,用于为每个问题生成代码样本;
- 一个采样机制,旨在生成多样化的代码样本,从而覆盖可能的程序解决方案空间;
- 一个过滤机制,用于剔除不符合问题描述的代码样本;
- 一个聚类算法,用于将语义上相似的代码样本分组,以此避免冗余;
- 一个评分模型,用于从每个最大的10个代码样本集群中筛选出最佳候选项。
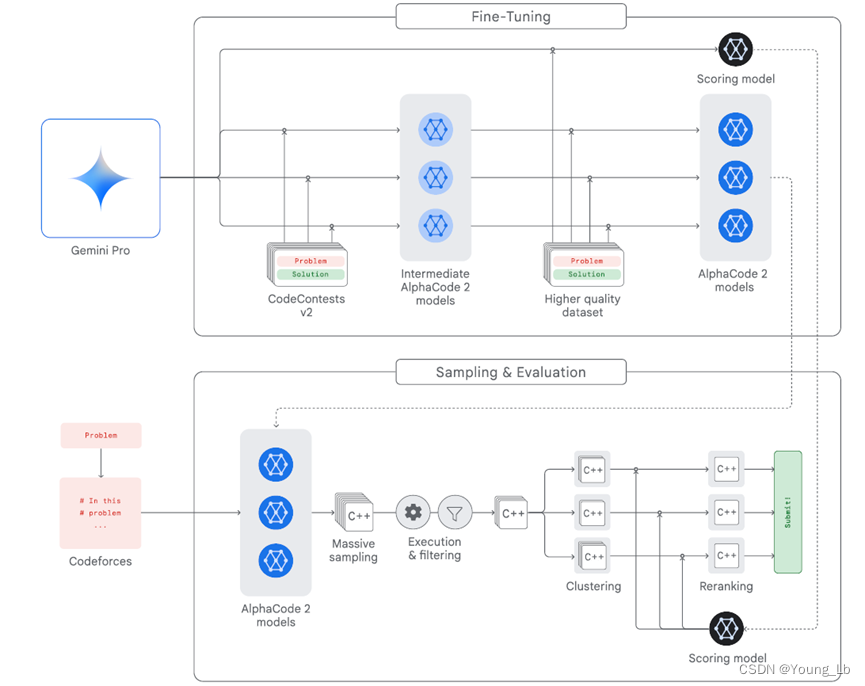
图 1 | AlphaCode 2 系统的高层次概述。
策略和微调
我们的起始点是 Gemini Pro 模型 (Gemini Team, Google, 2023),在此基础上,我们进行了两轮连续的微调,采用 GOLD (Pang and He, 2020) 作为训练目标。
首先,我们在 CodeContests 数据集 的更新版本上进行了微调。这个版本包含了更多问题、更多解决方案以及在验证集上手工策划的高质量测试,数据集大约包含 1.5 万个问题和 3000 万个人类编写的代码样本。我们通过调整超参数,生成了几个不同的微调模型,最终形成了一系列微调模型。接着,我们在另一个更高质量的数据集上进行了几步额外的微调。
使用一系列策略模型而非单一模型,使我们能够最大化解决方案的多样性,这对于解决复杂问题至关重要。
采样
我们的采样方法与 AlphaCode 相似。对于每个问题,我们生成多达一百万个代码样本,使用随机的温度参数来鼓励样本的多样性。我们还对提示中包含的目标元数据进行了随机化处理,例如问题的难度等级和分类标签。
我们将采样预算均匀分配给我们的一系列微调模型。虽然在 AlphaCode 中我们采样了 Python 和 C++,但在 AlphaCode 2 中我们仅使用 C++ 样本进行采样,因为我们发现它们的质量更高。
通过大规模采样,我们能够彻底探索模型分布,并生成大量多样化的代码样本,从而最大化至少生成一些正确样本的可能性。
考虑到样本数量众多,过滤和重新排序对整体系统性能至关重要。因为我们每个问题最多只提交 10 个代码样本。
过滤
每个竞赛编程问题都至少包含一个公开的输入/输出测试,用于指明代码样本应该表现出的行为。我们在相应的测试输入上运行每个代码样本,并剔除所有未产生预期输出的样本,因为这些样本显然不可能是正确的,同时也剔除了不到 5% 无法编译的样本。平均来说,这一过滤步骤移除了大约 95% 的样本。
聚类
经过过滤后,我们对每个问题平均留下了大约 5 万个候选代码样本,但我们将提交的解决方案限制在 10 个以内。为了进一步筛选候选样本,我们基于它们的运行时行为进行聚类:与 AlphaCode 相同,我们训练了一个独立的模型为每个问题生成新的测试输入,并在这些新输入上运行剩余的样本。这些样本产生的输出形成了一个我们用来将相似代码样本聚集在一起的“签名”。接着,我们根据集群的大小对其进行排序,并仅保留最大的 10 个集群。
聚类的目的是为了避免重复:由于同一集群中的代码样本表现相似,我们可以只提交每个集群中的一个样本给在线评判系统,以获得最佳结果。
评分模型
我们对另一个 Gemini Pro 模型进行了微调,使其能够为代码样本分配一个介于 0 到 1 之间的预估正确性分数。利用这个评分模型,我们为每个剩余集群中的代码样本计算一个分数;接着,我们基于这个预测分数从每个集群中挑选出最佳的候选样本,组成我们最终的 10 个提交方案。
评估
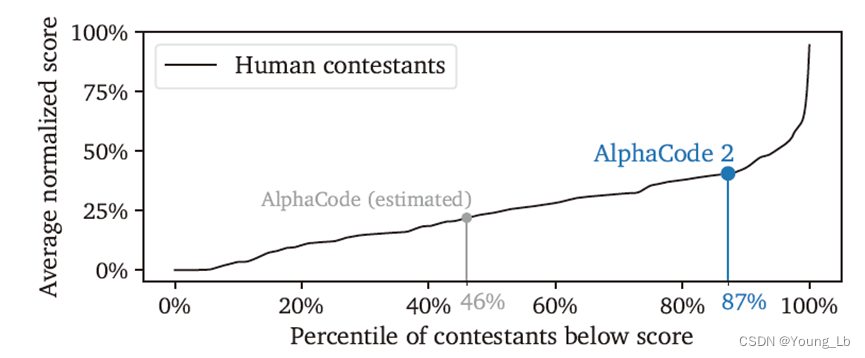
图 2 | AlphaCode 2 的估算排名。
我们绘制了 Codeforces 上人类竞争者的得分(将其除以每场比赛最佳人类得分进行 [0, 1] 的标准化)与他们的平均排名,基于我们评估的 12 场比赛。然后我们计算了 AlphaCode 2 的平均标准化得分,并将其映射到排名轴上,结果显示它舒适地位于 85 百分位以上。这个排名考虑到了一个假设:AlphaCode 2 按难度递增的顺序处理问题,并在 2 小时时限内完成最后一个问题的采样。
我们在 Codeforces 对 AlphaCode 2 进行了评估,这是与原始 AlphaCode 相同的平台。我们选取了 12 场最近的比赛,参赛者超过 8000 人,包括第 2 组或更高难度的 “1+2” 组。总共有 77 个问题。对于每个问题,我们采样了一百万个候选方案,并根据上述过程选择并排序的最多 10 个解决方案提交,直到找到正确的解决方案或用尽所有候选。
我们发现 AlphaCode 2 解决了这些竞赛问题的 43%,比之前创纪录的 AlphaCode 系统(解决了 25% 的问题)提高了近两倍。将这一成绩映射到竞赛排名上,我们估计 AlphaCode 2 平均位于前 15%,即其表现优于 85% 的参赛者,在 Codeforces 上介于“专家”和“候选大师”级别之间。这比 AlphaCode 的表现(仅优于估计的 46% 的竞争者)有显著提升。在表现最佳的两场比赛中,AlphaCode 2 的表现超过了超过 99.5% 的参赛者!
我们还评估了增加每个问题的样本数量对结果的影响。与 AlphaCode 相同,我们发现随着样本数量的增加,性能大致呈对数线性增长。AlphaCode 2 仅需大约 100 个样本便能达到 AlphaCode 使用一百万样本的性能水平,使其在样本效率上提高了超过 10000 倍。
讨论和结论
竞赛编程与其他编程任务有着显著不同,后者通常遵循命令式编程范式:用户提出明确的指令,模型输出相应的代码。然而,竞赛编程问题更加开放。解决这些问题需要先对其进行理解、分析和推理,这涉及到高级数学和计算机科学的概念。
这就解释了为什么通用的人工智能系统在这一基准测试中表现不佳。AlphaCode 2 在编程竞赛中取得的成功,代表了在这一极其困难的推理任务上性能的显著提升。
采用 Gemini Pro 作为我们的基础模型,对系统的两个关键部分——生成代码样本的策略模型和用于挑选最优样本的评分模型——带来了显著的性能提升。我们能够在这两个截然不同的任务上,将 Gemini 微调到高性能,这展现了它的卓越和灵活。我们推测,使用更先进的 Gemini Ultra 作为基础模型,凭借其在编程和推理能力上的提升,可能会进一步提高整个 AlphaCode 2 方法的性能。
尽管 AlphaCode 2 取得了令人印象深刻的成绩,但要实现能够稳定地达到顶尖人类程序员的性能的系统,还有许多工作要做。我们的系统需要大量试错,并且运行成本较高。此外,它在很大程度上依赖于能够过滤掉明显错误的代码样本。
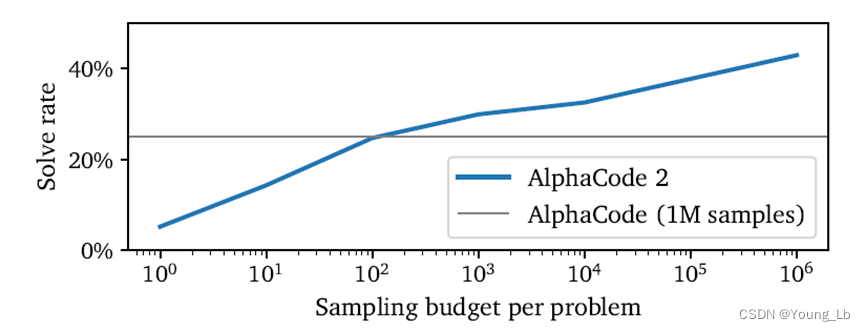
图 3 | 与每个问题样本数量相对应的 12 场近期比赛中的解决率。
这为系统与人类编码者之间的积极互动打开了新的可能,后者可以定义额外的过滤条件;在这种 AlphaCode 2 加人类的配置中,我们的得分超过了百分之九十的选手!我们希望这种交互式编程将成为编程的未来,程序员可以利用功能强大的人工智能模型作为合作工具,帮助他们思考问题、构思代码设计并协助实施。我们正致力于将 AlphaCode 2 的独特功能整合到我们的基础 Gemini 模型中,作为推广这种新编程范式的首步。
参考文献
- Gemini Team, Google. Gemini: A Family of Highly Capable Multimodal Models.2023. URL https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf.
- Leblond et al. AlphaCode 2 Technical Report. 2023. URL https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf.
- Y. Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. D. Lago, T. Hubert, P. Choy, C. de Masson d’Autume, I. Babuschkin, X. Chen, P.-S. Huang, J. Welbl, S. Gowal, A. Cherepanov, J. Molloy, D. J. Mankowitz, E. S. Robson, P. Kohli, N. de Freitas, K. Kavukcuoglu, and O. Vinyals. Competition-level code generation with alphacode. Science, 2022. URL https://www.science.org/doi/abs/10.1126/science.abq1158.
- R. Y. Pang and H. He. Text generation by learning from demonstrations. arXiv preprint arXiv:2009.07839, 2020. URL https://arxiv.org/pdf/2009.07839.pdf.
引用此工作
这是由谷歌 DeepMind 提供的一篇免费、开放获取的论文。这项工作的最终版本已在线发布。引用如下:
Leblond et al. AlphaCode 2 Technical Report. 2023. URL https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf.